Going beyond Langchain + Weaviate: Level 4 towards production
Preface
This post is part of a series of texts aiming to explore and understand patterns and practices that enable the construction of a production-ready AI data infrastructure. The series mainly focuses on the modeling and retrieval of evolving data, which would empower Large Language Model (LLM) apps and Agents to serve millions of users concurrently.
In this post, we delve into creating an initial data platform that can represent the core component of the future MlOps stack. Building a data platform is a big challenge in itself, and many solutions are available to help automate data tracking, ingestion, data contracting, monitoring, and warehousing.
In the last decade, data analytics and engineering fields have undergone significant transformations, shifting from storing data in centralized, siloed Oracle and SQL Server warehouses to a more agile, modular approach involving real-time data and cloud solutions like BigQuery and Snowflake.
Data processing evolved from an inessential activity, whose value would be inflated to please investors during the startup valuation phase, to a fundamental component of product development.
As we enter a new paradigm of interacting with systems through natural language, it's important to recognize that, while this method promises efficiency, it also comes with the challenges inherent in the imperfections of human language.
Suppose we want to use natural language as a new programming tool. In that case, we will need to either impose more constraints on it or make our systems more flexible so that they can adapt to the equivocal nature of language and information.
Our main goal should be to offer consistency, reproducibility and more that would ideally use language as a basic building block for things to come.
In order to come up with a set of solutions that could enable us to move forward, in this series of posts, we call on theoretical models from cognitive science and try to incorporate them into data engineering practices .
Level 4: Memory architecture and a first integration with keepi.ai
In our initial post, we started out conceptualizing a simple retrieval-augmented generation (RAG) model whose aim was to process and understand PDF documents.
We faced many bottlenecks in scaling these tasks, so in our second post, we needed to introduce the concept of memory domains.
In the next step, the focus was mainly on understanding what makes a good RAG considering all possible variables.
In this post, we address the fundamental question of the feasibility of extending LLMs beyond the data on which they were trained.
As a Microsoft research team recently stated:
- Baseline RAG struggles to connect the dots when answering a question requires providing synthesized insights by traversing disparate pieces of information through their shared attributes.
- Baseline RAG performs poorly when asked to understand summarized semantic concepts holistically over large data collections or even singular large documents.
To fill these gaps in RAG performance, we built a new framework — cognee.
Cognee combines human-inspired cognitive processes with efficient data management practices, infusing data points with more meaningful relationships to represent the (often messy) natural world in code more accurately.
Our observations indicate that systems, agents, and interactions often falter due to overextension and haste.
However, given the extensive demands and expectations surrounding Large Language Models (LLMs), addressing every aspect—agents, actions, integrations, and schedulers—is beyond the scope of the framework’s mission.
We've chosen to prioritize data, recognizing that the crux of many issues has already been addressed within the realm of data engineering.
We aim to establish a framework that includes file storage, tracing, and the development of robust AI memory data pipelines to help us manage and structure data more efficiently through its transformation processes.
Subsequently, our goal will be to devise methods for navigating diverse information segments and determine the most effective application of graph databases to store this data.
Our initial hypothesis—enhancing data management in vector stores through manipulative techniques and attention modulators for input and retrieval—proved less effective than anticipated.
Deconstructing and reorganizing data via graph databases emerged as a superior strategy, allowing us to adapt and repurpose existing tools for our needs more effectively.
| AI Memory type | State in Level 2 | State in Level 4 | Description |
|---|---|---|---|
| Sensory Memory | API | API | Can be interpreted in this context as the interface used for the human input |
| STM | Weaviate Class with hardcoded contract | Neo4j with a connection to a Weaviate class | The processing layer and a storage of the session/user context |
| LTM | Weaviate Class with hardcoded contract | Neo4j with a connection to a Weaviate class | The information storage |
On Level 4, we describe the integration of keepi, a chatGPT-powered WhatsApp bot that collects and summarizes information, via API endpoints.
Then, once we’ve ensured that we have a robust, scalable infrastructure, we deploy cognee to the cloud.
Workflow Overview
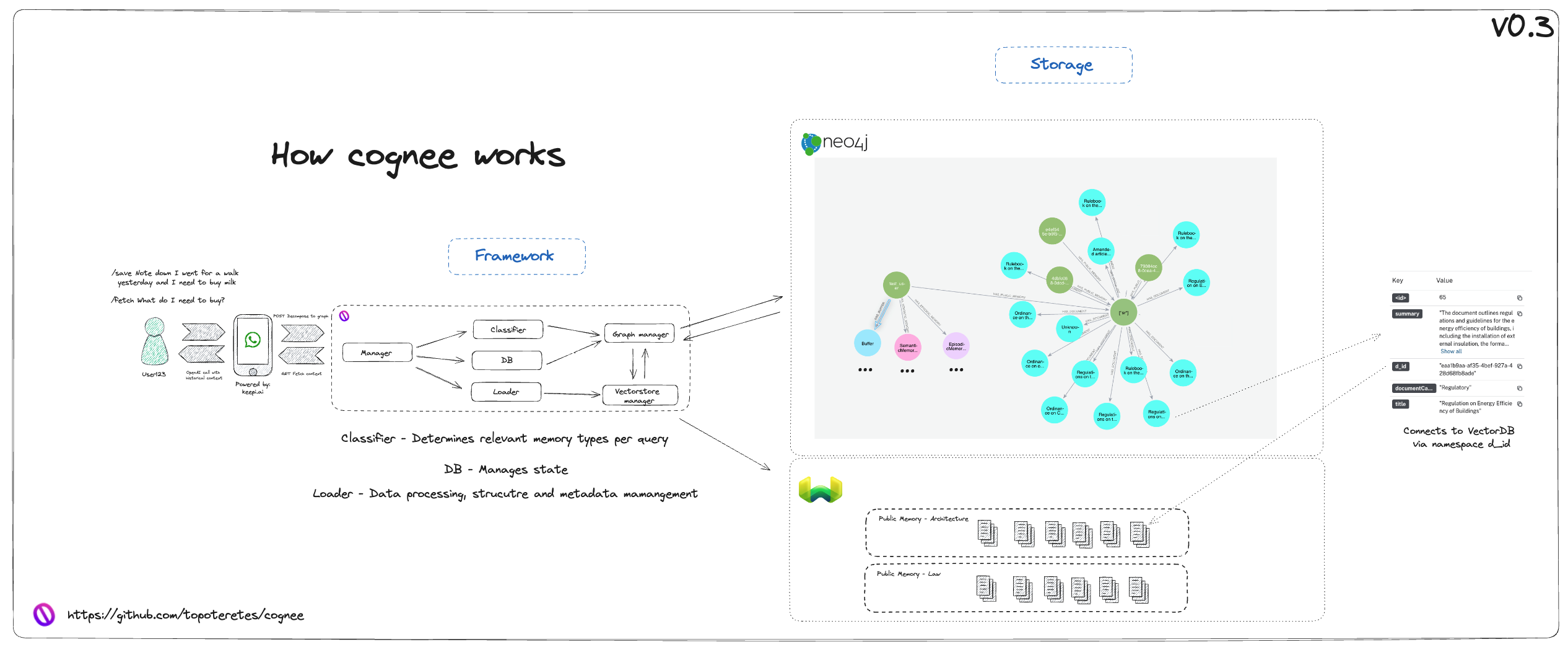
Steps:
- Users submit queries or documents for storage via the keepi.ai WhatsApp bot. This step integrates with the keepi.ai platform, utilizing Cognee endpoints for processing.
- The Cognee manager handles the incoming request and collaborates with several components:
- Relational database: Manages state and metadata related to operations.
- Classifier: Identifies, organizes, and enhances the content.
- Loader: Archives data in vector databases.
- The Graph Manager and Vector Store Manager collaboratively process and organize the input into structured nodes. A key function of the system involves breaking down user input into propositions—basic statements retaining factual content. These propositions are interconnected through relationships and cataloged in the Neo4j database by the Graph Manager, associated with specific user nodes. Users are represented by memory nodes that capture various memory levels, some of which link back to the raw data in vector databases.
What’s next
We're diligently developing our upcoming features, with key objectives including:
- Numerically defining and organizing the strengths of relationships within graphs.
- Creating a structured data model with opinions to facilitate document structure and data extraction.
- Converting Cognee into a Python library for easier integration.
- Broadening our database compatibility to support a broader range of systems.
Make sure to explore our implementation on GitHub, and, if you find it valuable, consider starring it to show your support.
Conclusion
If you enjoy the content or want to try out cognee please check out the github and give us a star!
Or
Big News: cognee raises €1.5 million to transform AI data management!
We're excited to announce that cognee has raised €1.5 million in funding! 🎉 This achievement isn't just a financial boost - it's a vote of confidence in our mission to make AI data management simpler, more cost-effective, and highly scalable for you.
4 mins read

Going beyond Langchain + Weaviate: Level 3 towards production
Enhancing RAG applications involves testing adjustable parameters like document quantity and chunk size. Challenges include reliably linking memories and organizing memory elements for human-like understanding. We need to ensure robust AI development.
7 mins read

Structured vs Unstructured Data - Types, Differences, Examples
Explore the key differences between structured and unstructured data, their applications, and best practices. Learn more about data types in modern analytics.
10 mins read