Going beyond Langchain + Weaviate: Level 3 towards production
Preface
This post is part of a series of texts aiming to explore and understand patterns and practices that enable the construction of a production-ready AI data infrastructure. The main focus of the series is on the modeling and retrieval of evolving data, which would empower Large Language Model (LLM) apps and Agents to serve millions of users concurrently.
For a broad overview of the problem and our understanding of the current state of the LLM landscape, check out our initial post here.
In this post, we delve into context enrichment and testing in Retrieval Augmented Generation (RAG) applications.
RAG applications can retrieve relevant information from a knowledge base and generate detailed, context-aware answers to user queries.
As we are trying to improve on the base information LLMs are giving us, we need to be able to retrieve and understand more complex data, which can be stored in various data stores, in many formats, and using different techniques.
All of this leads to a lot of opportunities, but also creates a lot of confusion in generating and using RAG applications and extending the existing context of LLMs with new knowledge.
1. Context Enrichment and Testing in RAG Applications
In navigating the complexities of RAG applications, the first challenge we face is the need for robust testing. Determining whether augmenting a LLM's context with additional information will yield better results is far from straightforward and often relies on subjective assessments.
Imagine, for instance, adding the digital version of the book The Adventures of Tom Sawyer to the LLM's database in order to enrich its context and obtain more detailed answers about the book's content for a paper we're writing. To evaluate this enhancement, we need a way to measure the accuracy of the responses before and after adding the book while considering the variations of every adjustable parameter.
2. Adjustable Parameters in RAG Applications
The end-to-end process of enhancing RAG applications involves various adjustable parameters, which offer multiple paths toward achieving similar goals with varying outcomes. These parameters include:
- Number of documents loaded into memory.
- Size of each sub-document chunk uploaded.
- Overlap between documents uploaded.
- Relationship between documents (Parent-Son etc.)
- Type of embedding used for data-to-vector conversion (OpenAI, Cohere, or any other embedding method).
- Metadata structure for data navigation.
- Indexes and data structures.
- Search methods (text, semantic, or fusion search).
- Output retrieval and scoring methods.
- Integration of outputs with other data for in-context learning.
- Structure of the final output.
3. The Role of Memory Manager at Level 3
Memory Layer + FastAPI + Langchain + Weaviate
3.1. Developer Intent at Level 3
The goal we set for our system in our initial post — processing and creating structured data from PDFs — presented an interesting set of problems to solve. OpenAI functions and dlthub allowed us to accomplish this task relatively quickly.
The real issue arises when we try to scale this task — this is what our second post tried to address. In addition, retrieving meaningful data from the Vector Databases turned out to be much more challenging than initially imagined.
In this post, we’ll discuss how we can establish a testing method, improve our ability to retrieve the information we've processed, and make the codebase more robust and production-ready.
We’ll primarily focus on the following:
-
Memory Manager
The Memory Manager is a set of functions and tools for creating dynamic memory objects. In our previous blog posts, we explored the application of concepts from cognitive science — Short-Term Memory, Long-Term Memory, and Cognitive Buffer — on Agent Network development.
We might need to add more memory domains to the process, as sticking to just these three can pose limitations. Changes in the codebase now enable real-time creation of dynamic memory objects, which have hierarchical relationships and can relate to each other.
-
RAG test tool
The RAG test tool allows us to control critical parameters for optimizing and testing RAG applications, including chunk size, chunk overlap, search type, metadata structure, and more.
The Memory Manager is a crucial component of any cognitive architecture platform. In our previous posts, we’ve discussed how to turn unstructured data to structured, how to relate concepts to each other in the vector store, and which problems can arise when productionizing these systems.
While we’ve addressed many open questions, many still remain. Based on our surveys and interviews with field experts, applications utilizing Memory components face the following challenges:
-
Inability to reliably link between Memories
Relying solely on semantic search or its derivatives to recognize the similarities between terms like "pair" and "combine" is a step forward. However, actually defining, capturing, and quantifying the relationships between any two objects would aid future memory access.
Solution: Graphs/Traditional DB
-
Failure to structure and organize Memories
We used OpenAI functions to structure and organize different Memory elements and convert them into understandable JSONs. Nevertheless, our surveys indicate that many people struggle with metadata management and the structure of retrievals. Ideally, these aspects should all be managed and organized in one place.
Solution: OpenAI functions/Data contracting/Metadata management
-
Hierarchy, size, and relationships of individual Memory elements
Although semantic search helps us understand the same concepts, we need to add more abstract concepts and ideas and link them. The ultimate goal is to emulate human understanding of the world, which comprises basic concepts that, when combined, create higher complexity objects.
Solution: Graphs/Custom solutions
-
Evaluation possibilities of memory components (can they be distilled to True/False)
Based on the psycholinguistic theories proposed by Walter Kintsch, any cognitive system should be able to provide True/False evaluations. Kintsch defines a basic memory component, a ‘proposition,’ which can be evaluated as True or False and can interlink with other Memory components.
A proposition could be, for example, "The sky is blue," and its evaluation to True/False could lead to actions such as "Do not bring an umbrella" or "Wear a t-shirt."
Potential solution: Particular memory structure
Testability of Memory components
We should have a reliable method to test Memory components, at scale, for any number of use-cases. We need benchmarks across every level of testing to capture and define predicted behavior.
Suppose we need to test if Memory data from six months ago can be retrieved by our system and measure how much it contributes to a response that spans memories that are years old.
Solution: RAG testing framework
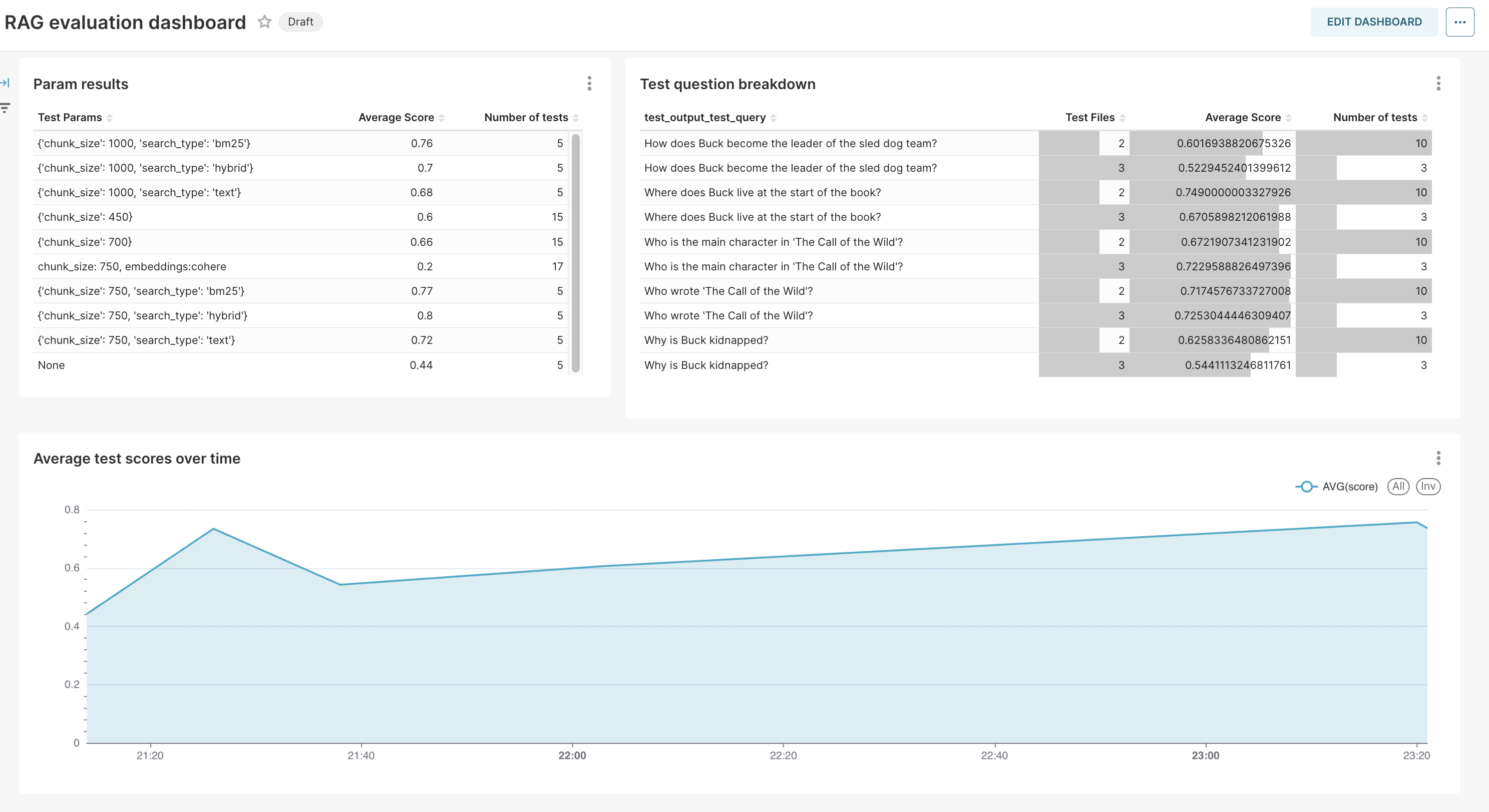
Let’s look at the RAG testing framework:
It allows to you to test and combine all variations of:
- Number of documents loaded into memory. ✅
- Size of each sub-document chunk uploaded. ✅
- Overlap between documents uploaded. ✅
- Relationship between documents (Parent-Son etc.) 👷🏻♂️
- Type of embedding used for data-to-vector conversion (OpenAI, Cohere, or any other embedding method). ✅
- Metadata structure for data navigation. ✅
- Indexes and data structures. ✅
- Search methods (text, semantic, or fusion search). ✅
- Output retrieval and scoring methods. 👷🏻♂️
- Integration of outputs with other data for in-context learning. 👷🏻♂️
- Structure of the final output. ✅
These parameters and results of the tests will be stored in Postgres database and can be visualized using Superset
To try it, navigate to: https://github.com/topoteretes/PromethAI-Memory
Copy the .env.template to .env and fill in the variables
Specify the environment variable in the .env file to "local"
Use the poetry environment:
Change the .env file Environment variable to "local"
Launch the postgres DB
Launch the superset
Open the superset in your browser
Add the Postgres datasource to the Superset with the following connection string:
Make sure to run to initialize DB tables
After that, you can run the RAG test manager from your command line.
Examples of metadata structure and test set are in the folder "example_data"
Conclusion
If you enjoy the content or want to try out cognee please check out the github and give us a star!
Or
What Do Most People Get Wrong About Knowledge Graphs?
Explore top knowledge graph mistakes and how to fix them. Learn about semantic relationships, graph enrichment, and AI memory. Begin your smarter data journey!
10 mins read

Fundraising in 2024
Discover how fundraising in 2024 in the AI infrastructure space looks like and how we went about securing 1.5m in funding. Join us in our journey growing cognee!
10 mins read

Structured vs Unstructured Data - Types, Differences, Examples
Explore the key differences between structured and unstructured data, their applications, and best practices. Learn more about data types in modern analytics.
10 mins read