Going beyond Langchain + Weaviate: Level 2 towards Production
1.1. The problem of putting code to production
This post is a part of a series of texts aiming to discover and understand patterns and practices that would enable building a production-ready AI data infrastructure. The main focus is on how to evolve data modeling and retrieval in order to enable Large Language Model (LLM) apps and Agents to serve millions of users concurrently.
For a broad overview of the problem and our understanding of the current state of the LLM landscape, check out our previous post
.png)
In this text, we continue our inquiry into what would constitute:
- Proper data engineering methods for LLMs
- A production-ready generative AI data platform that unlocks AI assistants/Agent Networks
To explore these points, we here at prometh.ai have partnered with dlthub in order to productionize a common use case — complex PDF processing — progressing level by level.
In the previous text, we wrote a simple script that relies on the Weaviate Vector database to turn unstructured data into structured data and help us make sense of it.
In this post, some of the shortcomings from the previous level will be addressed, including::
- Containerization
- Data model
- Data contract
- Vector Database retrieval strategies
- LLM context and task generation
- Dynamic Agent behavior and Agent tooling
3. Level 2: Memory Layer + FastAPI + Langchain + Weaviate
3.1. Developer Intent at Level 2
This phase enhances the basic script by incorporating:
-
Memory Manager
The memory manager facilitates the execution and processing of VectorDB data by:
- Uniformly applying CRUD (Create, Read, Update, Delete) operations across various classes
- Representing different business domains or concepts, and
- Ensuring they adhere to a common data model, which regulates all data points across the system.
-
Context Manager
This central component processes and analyzes data from Vector DB, evaluates its significance, and compares the results with user-defined benchmarks.
The primary objective is to establish a mechanism that encourages in-context learning and empowers the Agent’s adaptive understanding.
As an example, let’s assume we uploaded the book A Call of the Wild by Jack London to our Vector DB semantic layer, to give our LLM a better understanding of the life of sled dogs in the early 1900s.
Asking a question about the contents of the book will yield a straightforward answer, provided that the book contains an explicit answer to our question.
To enable better question answering and access to additional information such as historical context, summaries, and other documents, we need to introduce different memory stores and a set of attention modulators, which are meant to manage the prioritization of data retrieved for the answers.
-
Task Manager
Utilizing the tools at hand and guided by the user's prompt, the task manager determines a sequence of actions and their execution order.
For example, let’s assume that the user asks: “When was Buck (one of the dogs from A Call of the Wild) kidnapped” and to have the answer translated to German”
This query would be broken down by the task manager into a set of atomic tasks that can then be handed over to the Agent.
The ordered task list could be:
- Retrieve information about the PDF from the database.
- Translate the information to German.
-
The Agent
AI agents can use computers independently. They can browse the web, use apps, read and write files, make credit card payments, and even autonomously execute processes on your personal computer.
In our case, the Agent has only a few tools at its disposal, such as tools to translate text or structure data. Using these tools, it processes and executes tasks in the sequence they are provided by the Task Manager and the Context Manager.
3.2 Toward the memory layer - POC at level 2
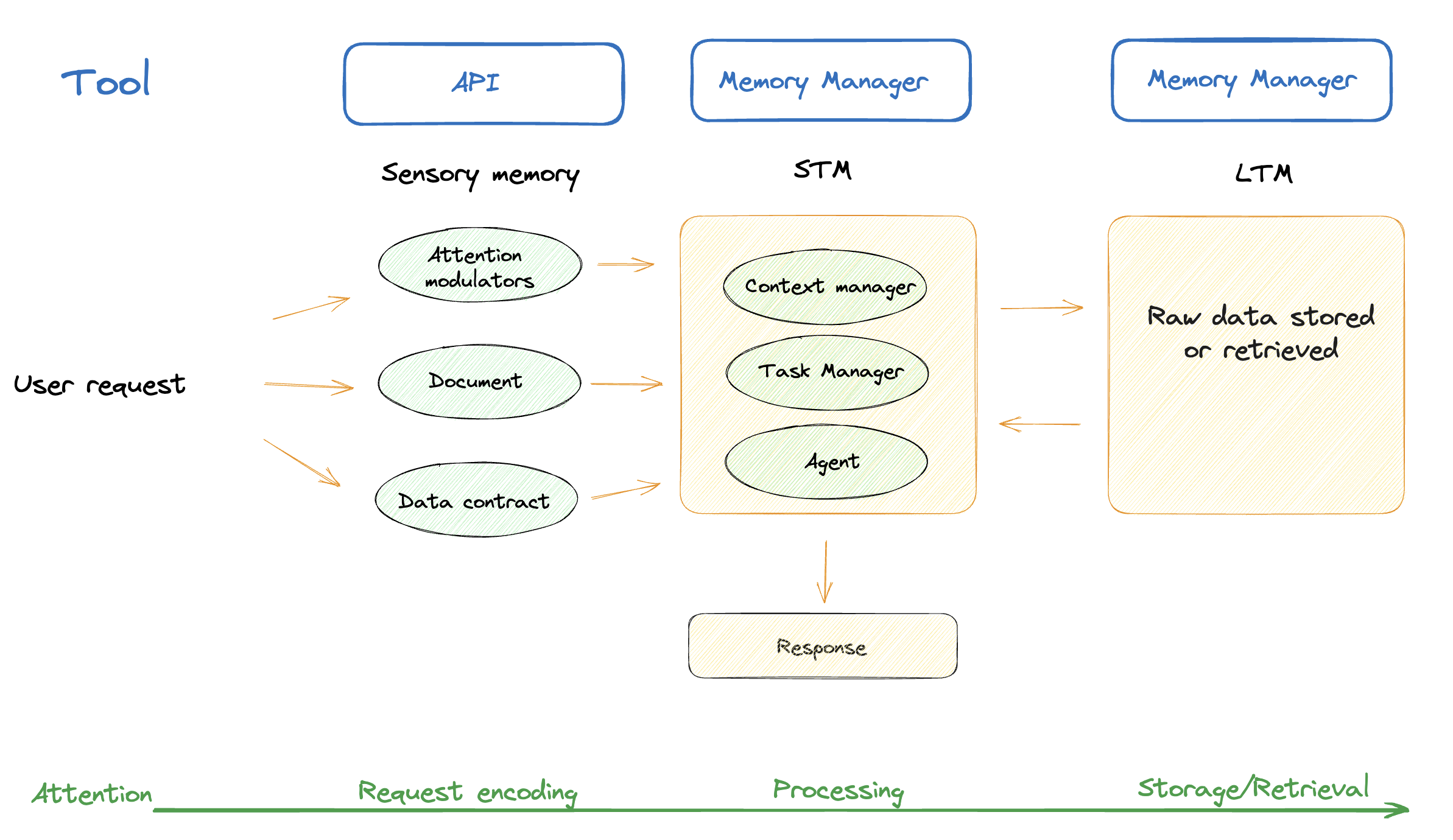
At this stage, our proof of concept (POC) allows uploading a PDF document and requesting specific actions on it such as "load to database", "translate to German", or "convert to JSON." Prior task resolutions and potential operations are assessed by the Context Manager and Task Manager services.
The following set of steps explains the workflow of the POC at level 2:
- Initially, we specify the parameters for the document we wish to upload and define our objective in the prompt:
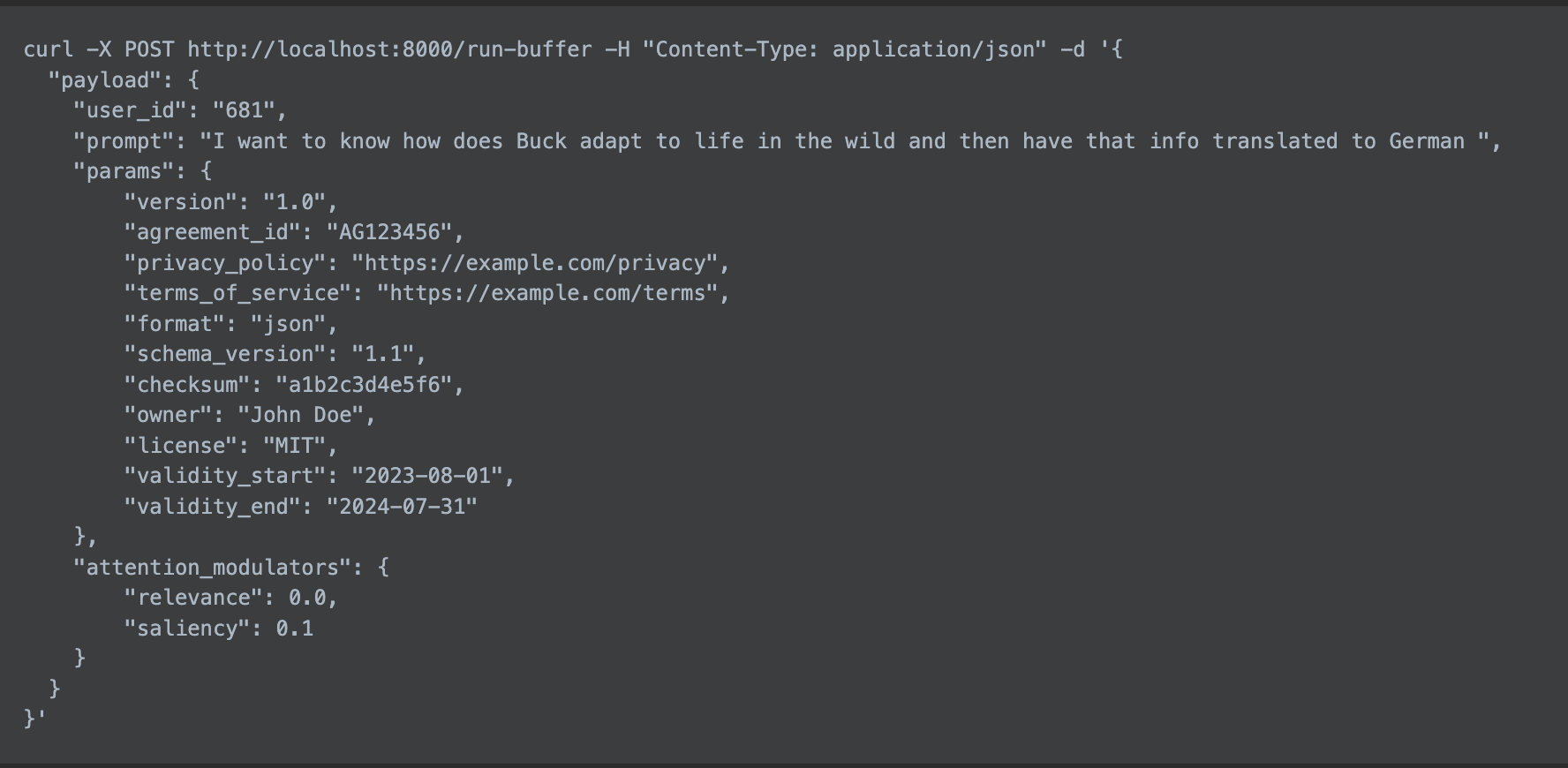
-
The memory manager retrieves the parameters and the attention modulators and creates context based on Episodic and Semantic memory stores (previous runs of the job + raw data):
.png)
-
To do this, it starts by filtering user input, in the same way our brains filter important from redundant information. As an example, if there are children playing and talking loudly in the background during our Zoom meeting, we can still pool our attention together and focus on what the person on the other side is saying.
The same principle is applied here:
.png)
-
In the next step, we apply a set of attention modulators to process the data obtained from the Vector Store.
NOTE: In cognitive science, attention modulators can be thought of as factors or mechanisms that influence the direction and intensity of attention.
As we have many memory stores, we need to prioritize the data points that we retrieve via semantic search.
Since semantic search is not enough by itself, scoring data points happens via a set of functions that replicate how attention modulators work in cognitive science.
Initially, we’ve implemented a few attention modulators that we thought could improve the document retrieval process:
Frequency: This refers to how often a specific stimulus or event is encountered. Stimuli that are encountered more frequently are more likely to be attended to or remembered.
Recency: This refers to how recently a stimulus or event was encountered. Items or events that occurred more recently are typically easier to recall than those that occurred a long time ago.
We have implemented many more, and you can find them in our
repository. More are still needed and contributions are more than welcome.
Let’s see the modulators in action:
.png)
In the code above we fetch the memories from the Semantic Memory bank where our knowledge of the world is stored (the PDFs). We select the relevant documents by using the handle_modulator function.
- The handle_modulator function is defined below and explains how scoring of memories happens.
.png)
We process the data retrieved with OpenAI functions and store the results for the Task Manager to be able to determine what actions the Agent should take.
The Task Manager then sorts and converts user input into a set of actionable steps based on the tools available.
.png)
Finally, the Agent interprets the context and performs the steps using the tools it has available. We see this as the step where the Agents take over the task, executing it in their own way.
Now, let's look back at what constitutes the Data Platform:
| Memory type | State | Description |
|---|---|---|
| Sensory Memory | API | Can be interpreted in this context as the interface used for the human input |
| STM | Weaviate Class with hardcoded contract | The processing layer and a storage of the session/user context |
| LTM | Weaviate Class with hardcoded contract | The information storage |
Lacks:
- Extendability: Capability to add features or functionality.
- Loading flexibility: Ability to apply different chunking strategies
- Testability: How to test the code and make sure it runs
Next Steps:
- Implement different strategies for vector search
- Add more tools to process PDFs
- Add more attention modulators
- Add a solid test framework
Conclusion
If you enjoy the content or want to try out cognee please check out the github and give us a star!
Or