Going beyond Langchain + Weaviate and towards a production ready modern data platform
1. Introduction: The Current Generative AI Landscape
1.1. A brief overview
Browsing the largest AI platform directory available at the moment, we can observe around 7,000 new, mostly semi-finished AI projects — projects whose development is fueled by recent improvements in foundation models and open-source community contributions.
Decades of technological advancements have led to small teams being able to do in 2023 what in 2015 required a team of dozens.
Yet, the AI apps currently being pushed out still mostly feel and perform like demos.
It seems it has never been easier to create a startup, build an AI app, go to market… and fail.
The consensus is, nevertheless, that the AI space is the place to be in 2023.
“The AI Engineer [...] will likely be the highest-demand engineering job of the [coming] decade.”
The stellar rise of AI engineering as a profession is, perhaps, signaling the need for a unified solution that is not yet there — a platform that is, in its essence, a Large Language Model (LLM), which could be employed as a powerful general problem solver.
To address this issue, dlthub and prometh.ai will collaborate on productionizing a common use-case, PDF processing, progressing step by step. We will use LLMs, AI frameworks, and services, refining the code until we attain a clearer understanding of what a modern LLM architecture stack might entail.
You can find the code in the PromethAI-Memory repository
1.2. The problem of putting code to production
Despite all the AI startup hype, there’s a glaring issue lurking right under the surface: foundation models do not have production-ready data infrastructure by default
Everyone seems to be building simple tools, like “Your Sales Agent” or “Your HR helper,” on top of OpenAI — a so-called “Thin Wrapper” — and selling them as services.
Our intention, however, is not to merely capitalize on this nascent industry — it’s to use a new technology to catalyze a true digital paradigm shift — to paraphrase investor Marc Andreessen, content of the new medium as the content of the previous medium.
What Andreessen meant by this is that each new medium for sharing information must encapsulate the content of the prior medium. For example, the internet encapsulates all books, movies, pictures, and stories from previous mediums.
After a unified AI solution is created, only then will AI agents be able to proactively and competently operate the browsers, apps, and devices we operate by ourselves today.
Intelligent agents in AI are programs capable of perceiving their environment, acting autonomously in order to achieve goals, and may improve their performance by learning or acquiring knowledge.
The reality is that we now have a set of data platforms and AI agents that are becoming available to the general public, whose content and methods were previously inaccessible to anyone not privy to the tech-heavy languages of data scientists and engineers.
As engineering tools move toward the mainstream, they need to become more intuitive and user friendly, while hiding their complexity with a set of background solutions.
Fundamentally, the issue of “Thin wrappers” is not an issue of bad products, but an issue of a lack of robust enough data engineering methods coupled with the general difficulties that come with creating production-ready code that relies on robust data platforms in a new space.
The current lack of production-ready data systems for LLMs and AI Agents opens up a gap we want to fill by introducing robust data engineering practices to solve this issue.
In this series of texts, our aim will thus be to explore what would constitute:
- Proper data engineering methods for LLMs
- A production-ready generative AI data platform that unlocks AI assistants/Agent Networks
Each of the coming blog posts will be followed by Python code, to demonstrate the progress made toward building a modern AI data platform, raise important questions, and facilitate an open-source collaboration.
Let’s start by setting an attainable goal. As an example, let’s conceptualize a production-ready process that can analyze and process hundreds of PDFs for hundreds of users.
Imagine you're a developer, and you've got a stack of digital invoices in PDF format from various vendors. These PDFs are not just simple text files; they contain logos, varying fonts, perhaps some tables, and even handwritten notes or signatures.
Your goal? To extract relevant information, such as vendor names, invoice dates, total amounts, and line-item details, among others.
This task of analyzing PDFs may help us understand and define what a production-ready AI data platform entails. To perform the task, we’ll be drawing a parallel between Data Engineering concepts and those from Cognitive Sciences which tap into our understanding of how human memory works — this should provide the baseline for the evaluation of the POCs in this post.
We assume that Agent Networks of the future would resemble groups of humans with their own memory and unique contexts, all working and contributing toward a set of common objectives.
In our example of data extraction from PDFs — a modern enterprise may have hundreds of thousands, if not millions of such documents stored in different places, with many people hired to make sense of them.
This data is considered unstructured — you cannot handle it easily with current data engineering practices and database technology. The task to structure it is difficult and, to this day, has always needed to be performed manually.
With the advent of Agent Networks, which mimic human cognitive abilities, we could start realistically structuring this kind of information at scale. As this is still data processing — an engineering task — we need to combine those two approaches.
From an engineering standpoint, the next generation Data Platform needs to be built with the following in mind:
- We need to give Agents access to the data at scale.
- We need our Agents to operate like human minds so we need to provide them with tools to execute tasks and various types of memory for reasoning
- We need to keep the systems under control, meaning that we apply good engineering practices to the whole system
- We need to be able to test, sandbox, and roll back what Agents do and we need to observe them and log every action
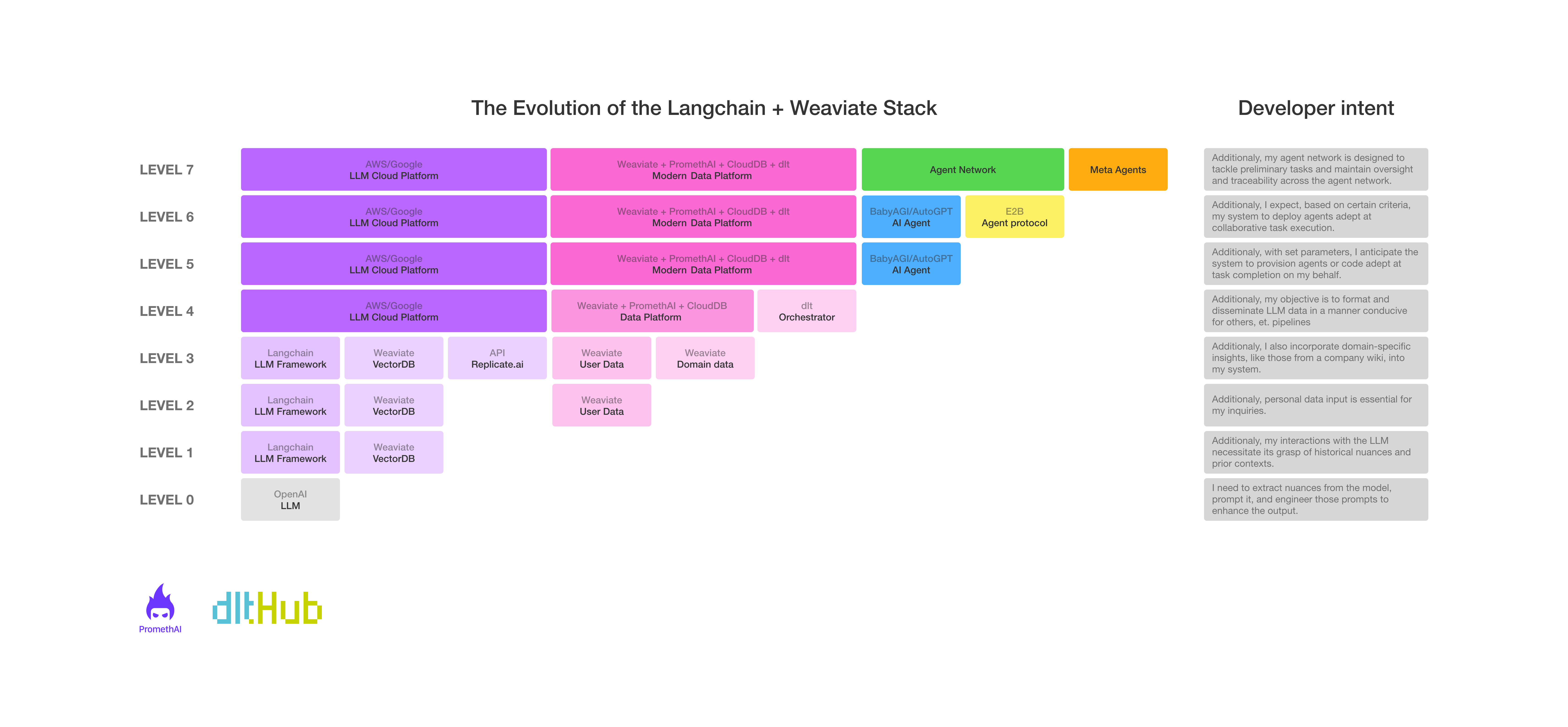
In order to conceptualize a new model of data structure and relationships that transcends the traditional Data Warehousing approach, we can start perceiving procedural steps in Agent execution flows as thoughts and interpreting them through the prism of human cognitive processes such as the functioning of our memory system and its memory components.
Human memory can be divided into several distinct categories:
- Sensory Memory (SM) → Very short term (15-30s) memory storage unit receiving information from our senses.
- Short Term Memory (STM) → Short term memory that processes the information, and coordinates work based on information provided.
- Long-Term Memory (LTM) → Stores information long term, and retrieves what it needs for daily life.
The general structure of human memory. Note that Weng doesn’t expand on the STM here in the way we did above:

Broader, more relevant representation of memory for our context, and the corresponding data processing, based on Atkinson-Schiffrin memory model would be:
2. Level 0: The Current State of Affairs
To understand the current LLM production systems, how they handle data input and processing, and their evolution, we start at Level 0 — the LLMs and their APIs as they are currently — and progress toward Level 7 — AI Agents and complex AI Data Platforms and Agent Networks of the future.
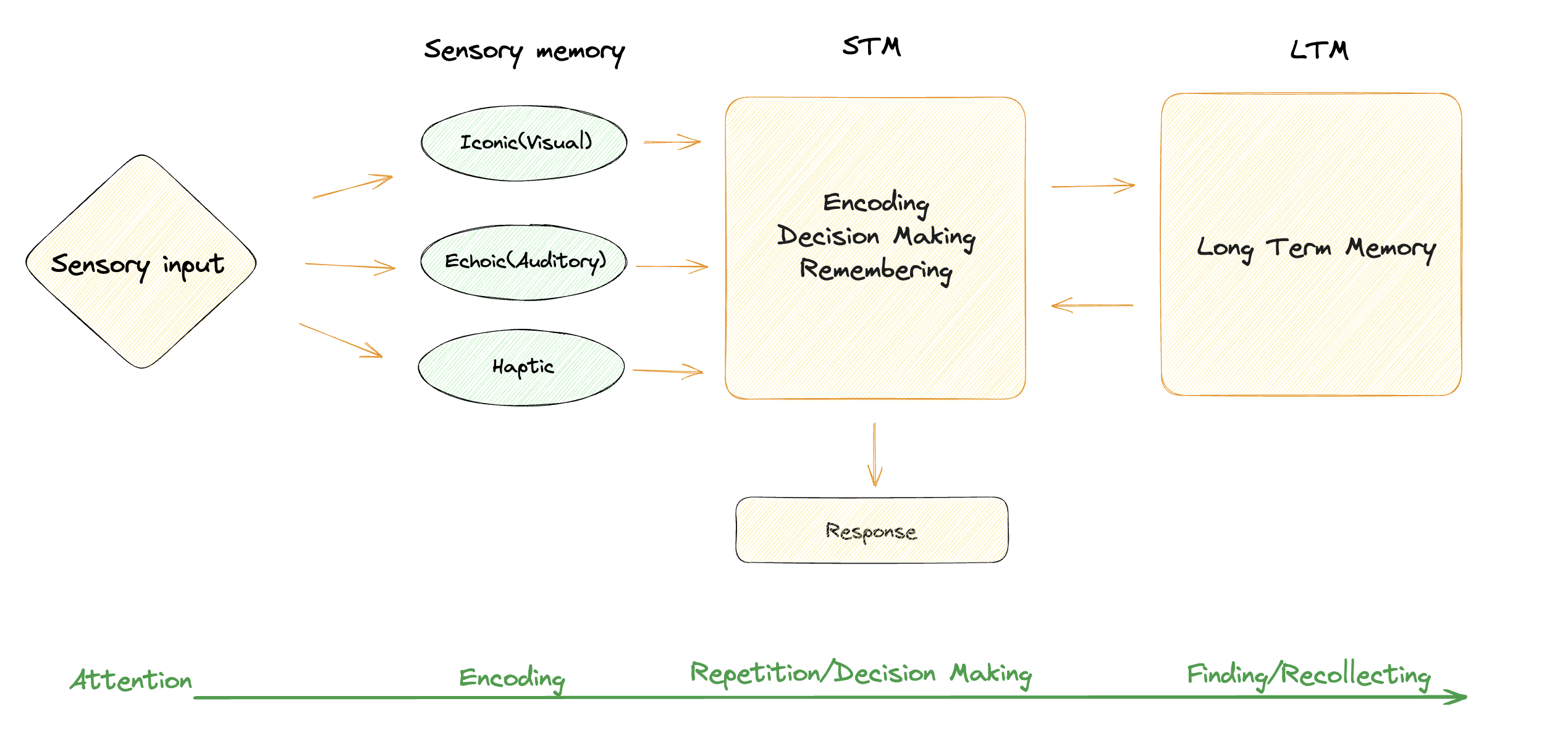
2.1. Developer Intent at Level 0
%201.png)
In order to extract relevant data from PDF documents, as an engineer you would turn to a powerful AI model like OpenAI, Anthropic, or Cohere (Layer 0 in our XYZ stack). Not all of them support this functionality, so you’d use Bing or a ChatGPT plugin like AskPDF, which do.
In order to "extract nuances," you might provide the model with specific examples or more directive prompts. For instance, "Identify the vendor name positioned near the top of the invoice, usually above the billing details."
Next, you'd "prompt it" with various PDFs to see how it reacts. Based on the outputs, you might notice that it misses handwritten dates or gets confused with certain fonts.
This is where "prompt engineering" comes in. You might adjust your initial prompt to be more specific or provide additional context. Maybe you now say, "Identify the vendor name and, if you find any handwritten text, treat it as the invoice date."
2.2 Toward the production code from the chatbot UX - POC at level 0
Our POC at this stage consists of simply uploading a PDF and asking it questions until we have better and better answers based on prompt engineering. This exercise shows what is available with the current production systems, to help us set a baseline for the solutions to come.
- If your goal is to understand the content of a PDF, Bing and OpenAI will enable you to upload documents and get explanations of their contents
- Uses basic natural language processing (NLP) prompts without any schema on output data
- Typically “forgets” the data after a query — no notion of storage (LTM)
- In a production environment, data loss can have significant consequences. It can lead to operational disruptions, inaccurate analytics, and loss of valuable insights
- There is no possibility to test the behavior of the system
Let’s break down the Data Platform component at this stage:
| Memory type | State | Description |
|---|---|---|
| Sensory Memory | Chatbot interface | Can be interpreted in this context as the interface used for the human input |
| STM | The context window of the chatbot/search. In essence stateless | The processing layer and a storage of the session/user context |
| LTM | Not present at this stage | The information storage |
Lacks:
- Decoupling: Separating components to reduce interdependency.
- Portability: Ability to run in different environments.
- Modularity: Breaking down into smaller, independent parts.
Extendability: Capability to add features or functionality.
Next Steps:
- Implement a LTM memory component for information retention.
- Develop an abstraction layer for Sensory Memory input and processing multiple file types.
Addressing these points will enhance flexibility, reusability, and adaptability.
2.3 Summary - Ask PDF questions
| Description | Use-Case | Summary | Memory | Maturity | Production readiness |
|---|---|---|---|---|---|
| The Foundational Model | Extract info from your documents | ChatGPT prompt engineering as the only way to optimise outputs | SM, STM are system defined, LTM is not present | Works 15% of time | Lacks Decoupling, Portability, Modularity and Extendability |
2.4. Addendum - companies in the space: OpenAI, Anthropic, and Cohere
-
A brief on each provider, relevant model and its role in the modern data space.
-
The list of models and providers in the space
Model Provider Structured data Speed Params Fine Tunability gpt-4 OpenAI Yes ★☆☆ - No gpt-3.5-turbo OpenAI Yes ★★☆ 175B No gpt-3 OpenAI No ★☆☆ 175B No ada, babbage, curie OpenAI No ★★★ 350M - 7B Yes claude Anthropic No ★★☆ 52B No claude-instant Anthropic No ★★★ 52B No command-xlarge Cohere No ★★☆ 50B Yes command-medium Cohere No ★★★ 6B Yes BERT Google No ★★★ 345M Yes T5 Google No ★★☆ 11B Yes PaLM Google No ★☆☆ 540B Yes LLaMA Meta AI Yes ★★☆ 65B Yes CTRL Salesforce No ★★★ 1.6B Yes Dolly 2.0 Databricks No ★★☆ 12B Yes
3. Level 1: Langchain & Weaviate
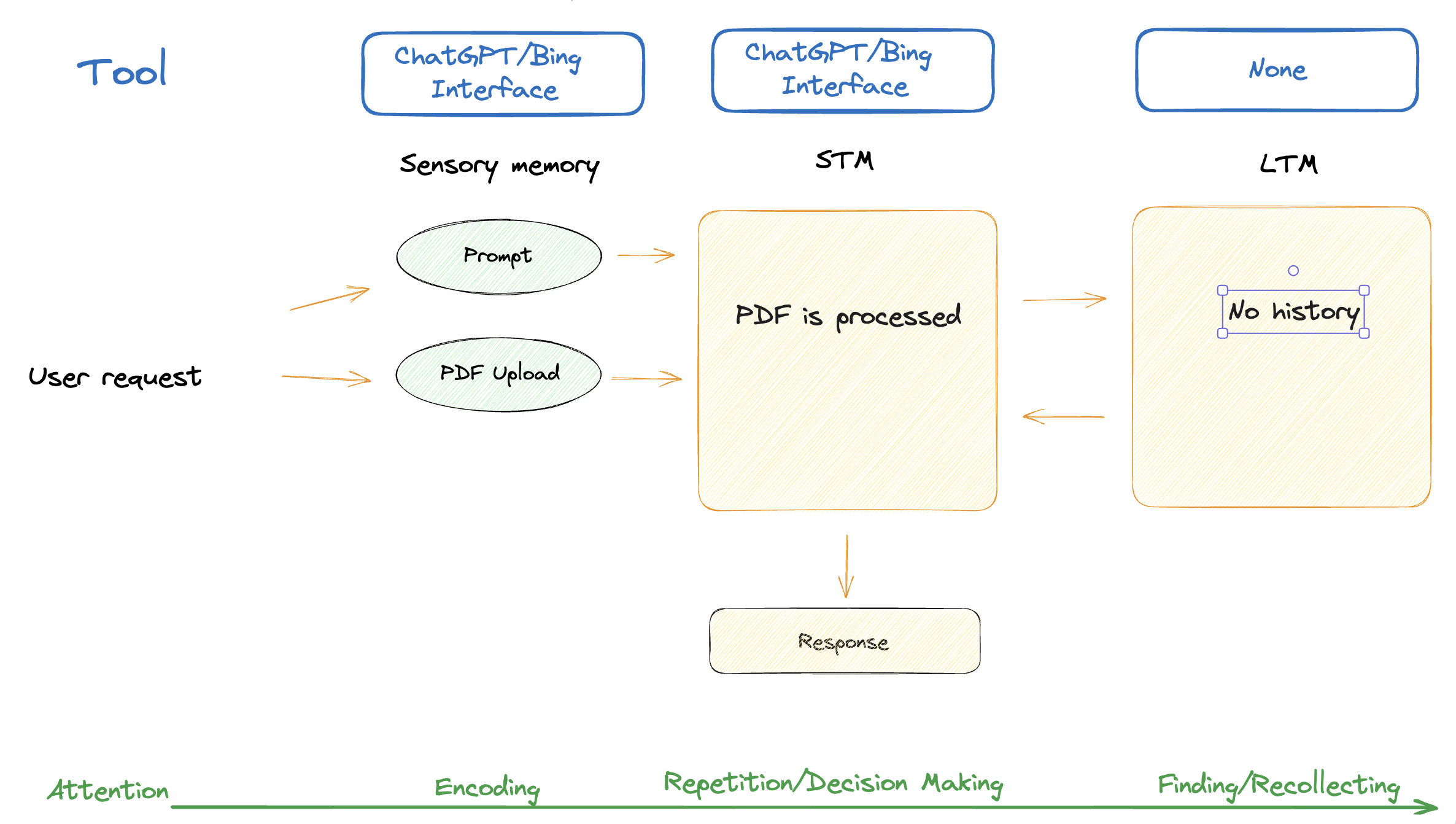
3.1. Developer Intent at Level 1: Langchain & Weaviate LLM Wrapper
%202.png)
This step is basically an upgrade to the current state of the art LLM UX/UI where we add:
-
Permanent LTM memory (data store)
As a developer, I need to answer questions on large PDFs that I can’t simply pass to the LLM due to technical limitations. The primary issue being addressed is the constraint on prompt length. As of now, GPT-4 has a limit of 4k tokens for both the prompt and the response combined. So, if the prompt comprises 3.5k tokens, the response can only be 0.5k tokens long.
-
LLM Framework like Langchain to adapt any document type to vector store
Using Langchain provides a neat abstraction for me to get started quickly, connect to VectorDB, and get fast results.
-
Some higher level structured storage (dlthub)
3.2. Translating Theory into Practice: POC at Level 1
- LLMs can’t process all the data that a large PDF could contain. So, we need a place to store the PDF and a way to retrieve relevant information from it, so it can be passed on to the LLM.
- When trying to build and process documents or user inputs, it’s important to store them in a Vector Database to be able to retrieve the information when needed, along with the past context.
- A vector database is the optimal solution because it enables efficient storage, retrieval, and processing of high-dimensional data, making it ideal for applications like document search and user input analysis where context and similarity are important.
- For the past several months, there has been a surge of projects that personalize LLMs by storing user settings and information in a VectorDB so they can be easily retrieved and used as input for the LLM.
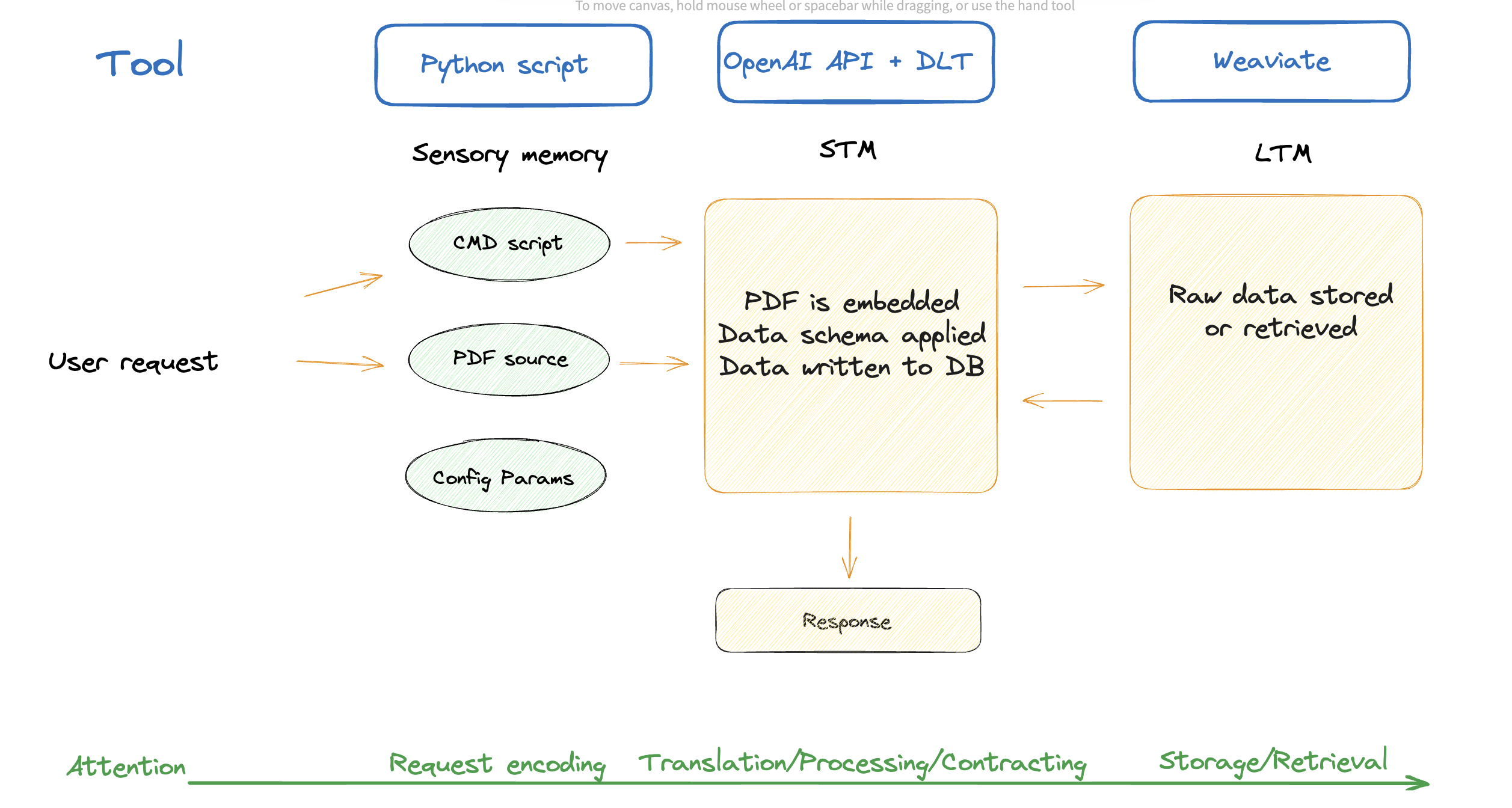
This can be done by storing data in the Weaviate Vector Database; then, we can process our PDF.
- We start by converting the PDF and translating it
.png)
- the next step we store the PDF to Weaviate
.png)
- We load the data into some type of database using dlthub
.png)
The parallel with our memory components becomes clearer at this stage. We have some way to define inputs which correspond to SM, while STM and LTM are starting to become two separate, clearly distinguishable entities. It becomes evident that we need to separate LTM data according to domains it belongs to but, at this point, a clear structure for how that would work has not yet emerged.
In addition, we can treat GPT as limited working memory and its context size as how much our model can remember during one operation.
It’s evident that, if we don’t manage the working memory well, we will overload it and fail to retrieve outputs. So, we will need to take a closer look into how humans do the same and how our working memory manages millions of facts, emotions, and senses swirling around our minds.
Let’s break down the Data Platform components at this stage:
| Memory type | State | Description |
|---|---|---|
| Sensory Memory | Command line interface + arguments | Can be interpreted in this context as the arguments provided to the script |
| STM | Partially Vector store, partially working memory | The processing layer and a storage of the session/user context |
| LTM | Vector store | The raw document storage |
Sensory Memory
Sensory memory can be seen as an input buffer where the information from the environment is stored temporarily. In our case, it’s the arguments we give to the command line script.
STM
STM is often associated with the concept of "working memory," which holds and manipulates information for short periods.
In our case, it is the time during which the process runs.
LTM
LTM can be conceptualized as a database in software systems. Databases store, organize, and retrieve data over extended periods. The information in LTM is organized and indexed, similar to how databases use tables, keys, and indexes to categorize and retrieve data efficiently.
VectorDB: The LTM Storage of Our AI Data Platform
Unlike traditional relational databases, that store data in tables, and newer NoSQL databases like MongoDB, that use JSON documents, vector databases specifically store and fetch vector embeddings.
Vector databases are crucial for Large Language Models and other modern, resource-hungry applications. They're designed for handling vector data, commonly used in fields like computer graphics, Machine Learning, and Geographic Information Systems.
Vector databases hinge on vector embeddings. These embeddings, packed with semantic details, help AI systems to understand data and retain long-term memory. They're condensed snapshots of training data and act as filters when processing new data in the inference stage of machine learning.
Problems:
- Interoperability
- Maintainability
- Fault Tolerance
Next steps:
- Create a standardized data model
- Dockerize the component
- Create a FastAPI endpoint
3.4. Summary - The thing startup bros pitch to VCs
| Description | Use-Case | Summary | Knowledge | Maturity | Production readiness |
|---|---|---|---|---|---|
| Interface Endpoint for the Foundational Model | Store data and query it for a particular use-case | Langchain + Weaviate to improve user’s conversations + prompt engineering to get better outputs | SM is somewhat modifiable, STM is not clearly defined, LTM is a VectorDB | Works 25% of time | Lacks Interoperability, Maintainability, Fault Tolerance Has some: Reusability, Portability, Extendability |
3.5. Addendum - Frameworks and Vector DBs in the space: Langchain, Weaviate and others
-
A brief on each provider, relevant model and its role in the modern data space.
-
The list of models and providers in the space
Tool/Service Tool type Ease of use Maturity Docs Production readiness Langchain Orchestration framework ★★☆ ★☆☆ ★★☆ ★☆☆ Weaviate VectorDB ★★☆ ★★☆ ★★☆ ★★☆ Pinecone VectorDB ★★☆ ★★☆ ★★☆ ★★☆ ChromaDB VectorDB ★★☆ ★☆☆ ★☆☆ ★☆☆ Haystack Orchestration framework ★★☆ ★☆☆ ★★☆ ★☆☆ Huggingface's New Agent System Orchestration framework ★★☆ ★☆☆ ★★☆ ★☆☆ Milvus VectorDB ★★☆ ★☆☆ ★★☆ ★☆☆ https://gpt-index.readthedocs.io/ Orchestration framework ★★☆ ★☆☆ ★★☆ ★☆☆
Resources
Blog Posts:
- Large Action Models
- Making Data Ingestion Production-Ready: A LangChain-Powered Airbyte Destination
- The Problem with LangChain
Research Papers (ArXiv):
Web Comics:
Reddit Discussions:
Developer Blog Posts:
Industry Analysis:
Prompt Engineering:
Conclusion
If you enjoy the content or want to try out cognee please check out the github and give us a star!
Or
Memory Fragment Projection: Building a Personalized Knowledge Graph Layer with Cognee
Learn creating personalized knowledge graphs through memory fragment projection. Use cognee's retrieval process and GraphRAG pipelines for better data exploration.
8 mins read

Knowledge Graph Query Answering (KGQA) with Cognee
Learn how Knowledge Graph question answering, Retrieval-Augmented Generation, and AI anomaly detection drive AI-powered search & personalized recommendations.
10 mins read

cognee & LlamaIndex: Building Powerful GraphRAG Pipelines
Learn to build GraphRAG pipelines with cognee and LlamaIndex, handling structured and unstructured data in LLM workflows for improved accuracy. Try it now!
7 mins read